PDF扫描文档全部由图片组成,文本不能直接复制。如果你想制作一个有图片的双层pdf文件,同时也直接复制文本,你怎么实现呢?我们可以使用Acrobat软件,也可以使用软件自带的OCR识别工具,给PDF文档增加一个透明的文本层,从而制作出双层PDF。PDF看起来像扫描文档,但它可以直接复制文本。让我们来看看详细的教程。
软件名称:adobe acrobat xi pro v11.0.10简体中文安装软件大小:770MB更新时间:2015年4月3日立即下载1。以下是扫描生成的PDF文档。可见文字是不能直接复制的。
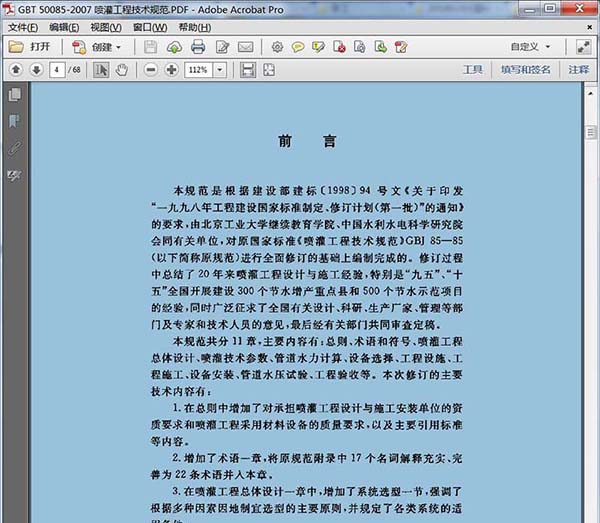
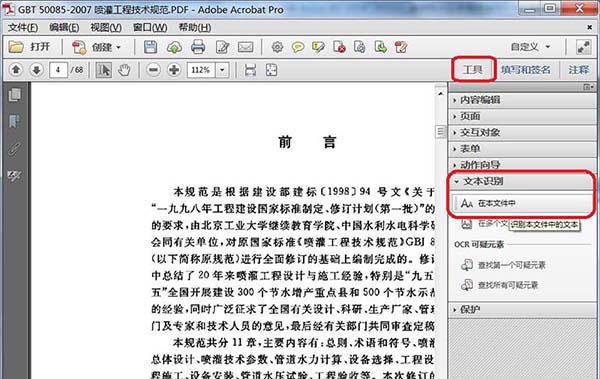
2.单击Acrobat软件工具栏右上角的“工具”选项,打开“文本识别”,然后单击“在此文件中”。
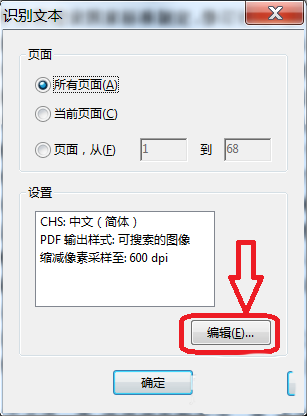
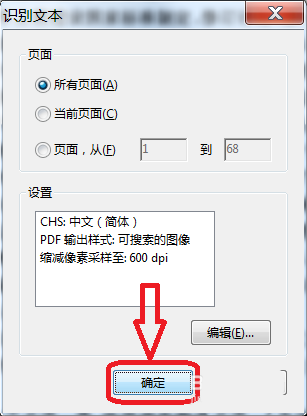
3.在弹出的“识别文本”对话框中,点击“编辑”设置文本识别参数。
4.字符识别参数设置:OCR识别的主要语言(此处选择简体中文);
PDF输出样式:可搜索图像、可搜索图像(精确)、ClearScan(这里保留默认);
将像素采样降低到:600、300、150、72dpi(如果要打印,建议不要低于150dpi)。
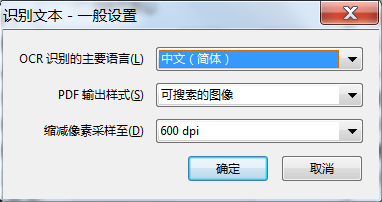
5.设置字符识别参数后,点击确定开始字符识别。
6.可以看到软件界面底部有一个字符识别进度条。如果文件大,识别时间会更长,这是我们可以做到的。
7.文本识别完成后,可以看到可以通过文本选择工具进行选择。可以看出识别准确率还是比较高的。如果需要校对文字,可以参考相关教程。

8.通过对比可以看出,添加透明文本层对源文件的大小影响不大。

以上是从扫描的PDF制作可复制文本的双层PDF教程。希望你喜欢。请继续关注。
相关建议:
Acrobat如何在PDF中添加用户签名?
Acrobat Pro是如何把PDF文件中的所有文字翻过来的?
Acrobat2018如何使用OCR识别扫描PDF中的文本?

 萌导航
萌导航 pp加速器
pp加速器 邮乐网
邮乐网 yowa云游戏手机版
yowa云游戏手机版 哈屏壁纸免费版
哈屏壁纸免费版 安卓壁纸大师app
安卓壁纸大师app webtoon漫画中文版
webtoon漫画中文版 小黄人影视2024最新版
小黄人影视2024最新版 南瓜车管家
南瓜车管家 锦江酒店
锦江酒店 看怀集
看怀集 抬腕应用商店最新
抬腕应用商店最新 腾讯会议手机版
腾讯会议手机版 圣婴阅读
圣婴阅读 柠檬英语软件
柠檬英语软件 苗苗清理大师
苗苗清理大师 夸磁浏览器app
夸磁浏览器app 提瓦特小助手安卓版
提瓦特小助手安卓版 硬汗健身
硬汗健身 亲亲漫画
亲亲漫画





