Dplyr专注于处理dataframe对象,并提供了与其他数据库对象更健壮的接口。
一个或五个关键数据处理功能:
Select()返回列的子集filter()返回行的子集arrange()根据一个或多个变量对行进行排序。Mutate()使用现有数据创建一个新列,summarise()汇总每个组的计算结果并返回一维结果。
提示:
1、选择()
Dplyr包具有以下辅助功能,用于在select()中选择变量:
以(' X ')开头_ :变量名以(' X ')结尾_ :变量名包含(' X'):变量名匹配(' X'):以' X '匹配正则表达式“X '”:5):变量名是x01、x02、x03、x04和x05其中一个_的(x) :字符向量X中出现的所有变量名。
在select()中直接使用列时,不需要引用“”,但在使用上述辅助函数时,必须引用“”。
2、过滤器()
r有一系列可在filter()中使用的逻辑表达式:
x y;x=y;x==y;x!=y;x=y;x y;% c中的x %(a,b,c)
示例:
滤波器(df,a 0,b 0)
过滤器(df,is.na(x))
3、排列()
默认情况下,array()从小到大排序,desc()对array()中的变量进行操作,将它们从大到小排序。
4、突变()
Mutate()允许在同一调用中使用新变量来创建下一个变量,例如:
突变(my_df,x=a b,y=x c)
5、总结()
r的下列聚合函数可用于总结()
最小(x)-最小。max(x)-max。均值(x)-均值(x)-中值分位数(x,p)-第p个分位数SD(x)-标准差var(x)-方差IQR(x)-四分位数diff (range (x))
first(x)-向量x中的第一个元素last(x)-最后一个元素n(x,n)-第n个元素n()-数据. frame中的行数或由summer()n _ distinct(x)描述的观察组数-向量x II中唯一值的数量。管道功能%%
dplyr包中唯一的管道函数%%将前一个函数的输出作为下一个函数的输入。
%%运算符允许从参数列表中提取函数的第一个参数,并将其放在%%之前。
以下两条指令是相同的:
平均值(c(1,2,3,NA),na.rm=真)
c(1,2,3,NA) %%平均值(na.rm=真)
Iii .分组函数group_by()
为数据集定义组。然后每组可以分别汇总统计。
通过group_by()添加分组信息后,mutate()、arrange()和summarise()函数将自动对这些tbl类数据执行分组操作。
group_by(dataframe,colnames1,colnames2,…)
第四,连接数据(连接)
1、6种连接功能如下:
left_join(dataset1,dataset2)right_join(dataset1,dataset2)
inner_join(dataset1,dataset2,by=c(" ")
full_join(dataset1,dataset2,by=c('first ',' last ')
semi_join(dataset1,dataset2,by=c('first ',' last ')
anti_join(dataset1,dataset2,by=c('first ',' last ')
前四个属于变异连接,后两个属于过滤连接。
半连接基于第二数据集的信息过滤第一数据集的数据。反连接会在合并时找出哪些行与第二个数据集不匹配

2.关键字值
R语言中的数据框可以将重要信息存储在row.names属性中,虽然这不是一种很好的存储数据的方式,但却很常见。如果数据集的主键在row.names中,将很难与其他数据集连接。一种解决方案是使用tibble包(Tibble:一个带有类TBL _ df的数据框)中的rownames_to_column()函数返回数据集的副本,行名作为列添加到数据中。
图书馆
rownames _ to _ column(数据,var='name ')
如果两个数据集具有相同的列名但表示不同的内容,并且by参数不包含这些重复的列名,则dplyr将忽略这些列名并添加。x和。y添加到相同的列名,以帮助区分列。
当两个数据集中的相同事物具有不同的列名时,要完成合并,由设置为命名向量。向量的名称是主数据集中的列名,向量的值是第二个数据集中的列名。例如:
x %% left_join(y,by=c('x.name'='y.name '))
连接完成后,在主数据集中保留列名。
3.多个数据集的连接
purr包中的reduce()函数将一个函数反复应用于多个数据集,可用于连接多个数据集,并与dplyr的join类函数结合使用,如:library(purr)list(data 1,data2,data3)%% reduce (left _ join,by=c ('first ',' last ')
动词(verb的缩写)集合运算
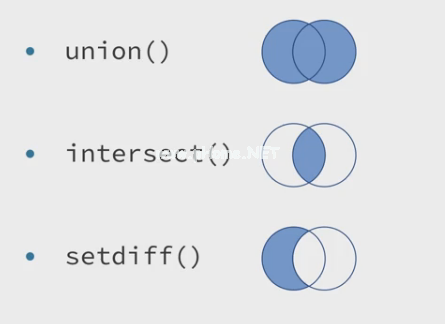
Dplyr提供交集、并集和setdiff来获取数据集的交集、并集和差集。
不及物动词汇编数据
使用以下功能:
bind _ rows()
Bind_cols():将多个数据框组合成一个数据框
Data_frame() :将一系列列向量组合成一个数据帧
As_data_frame() :将列表转换为数据帧
以上对数据处理包dplyr功能使用的总结是边肖分享的全部内容,希望能给大家一个参考和支持。

 萌导航
萌导航 pp加速器
pp加速器 邮乐网
邮乐网 yowa云游戏手机版
yowa云游戏手机版 哈屏壁纸免费版
哈屏壁纸免费版 安卓壁纸大师app
安卓壁纸大师app webtoon漫画中文版
webtoon漫画中文版 小黄人影视2024最新版
小黄人影视2024最新版 南瓜车管家
南瓜车管家 锦江酒店
锦江酒店 看怀集
看怀集 抬腕应用商店最新
抬腕应用商店最新 腾讯会议手机版
腾讯会议手机版 圣婴阅读
圣婴阅读 柠檬英语软件
柠檬英语软件 苗苗清理大师
苗苗清理大师 夸磁浏览器app
夸磁浏览器app 提瓦特小助手安卓版
提瓦特小助手安卓版 硬汗健身
硬汗健身 亲亲漫画
亲亲漫画





