最近,创建了一个供用户发表评论的功能。用户上传评论,然后可以在文章下面看到自己的评论。但作为社会主义接班人,他们践行社会主义核心价值观,因此过滤敏感词进行评论的功能不可或缺。在网上搜索资料后,我们发现已经有了非常成熟的解决方案。常用的解决方案使用这两种
1.全文搜索,一一匹配。这种声音不够高。在数据量很大的情况下,会出现效率问题,文章最后会有比较
2.DFA算法——确定有限状态自动机用百科链接确定有限状态自动机
DFA算法介绍
DFA是一个计算模型,数据源是一个有限集合。下一个状态由当前状态和事件决定,即状态事件=下一个状态,然后逐步构造有向图,其中节点为状态。因此,在DFA算法中,只有搜索和判断,没有复杂的计算,从而提高了算法的效率。
参考文章Java过滤敏感词
实现逻辑
构建数据结构
将敏感词转换成树形结构。比如敏感词['日本鬼子','日本人']太多,所以数据结构如下(图片参考参考文章)
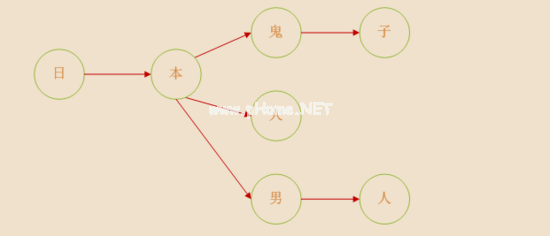
每个字符都是一个节点,连续的节点组成一个单词。日本人对应的是中链。我们可以用物体或地图来建造树木。在这里,栗子使用map来构建节点,每个节点都有一个状态标识符来指示当前节点是否是最后一个节点。每个链接必须有一个结束节点。首先看构建节点的流程图。
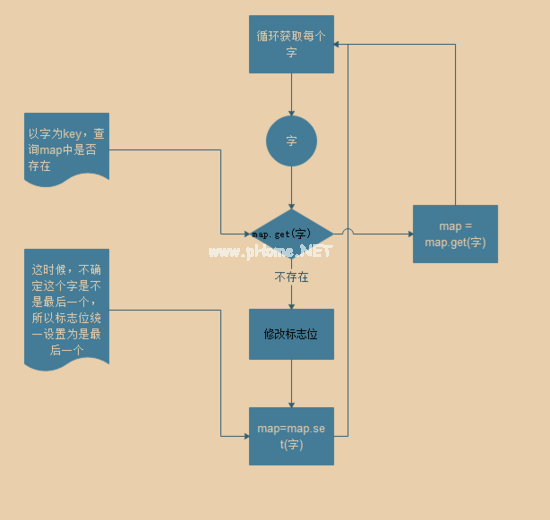
判断逻辑
首先,从课文的第一个单词开始检查。比如你我都是日本鬼子。如果在树的第一层找不到这个节点,那就继续找第二个单词。找到第一级节点后,再在下一级节点寻找Ben,判断这个节点是否为结束节点。如果是端节点,则匹配成功,否则继续匹配。
代码实现
# # # #构建数据结构
/*** @description*构造敏感词映射* @ private * @返回*/private makesensitive map(敏感词列表){//构造根节点const result=new Map();for(敏感单词列表的常量单词){ let map=resultfor(设I=0;I .字长;I) {//依次得到const char=word.charAt(i)这个词;//判断是否if (map。get (char))存在{//获取下一个节点映射=map . get(char);} else {//如果(map . get(' laster ')==true){ map . set(' laster ',false),则将当前节点设置为非结束节点;} const item=new Map();//新节点默认为结束节点item.set('laster ',true);map.set(char,item);map=map . get(char);} } }返回结果;}最终的地图结构如下
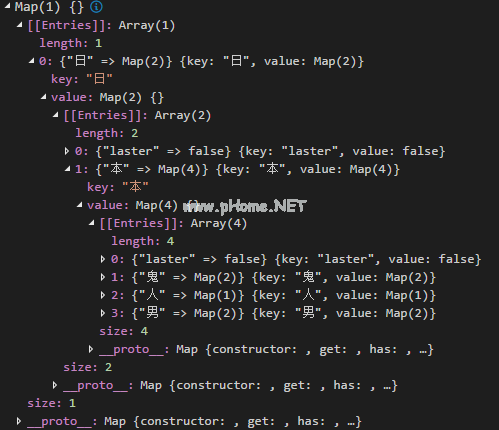
查找敏感词
/*** @description*检查敏感词是否存在* @ private * @ param { any } txt * @ param { any } index * @返回*/private check敏感词(敏感映射、txt、index){让当前映射=敏感映射;let flag=false让WordNum=0;//记录过滤器让敏感词=' ';//记录筛选出的敏感词为(let i=indexi txt.lengthI){ const word=txt . charat(I);current map=current map . get(word);if(CurrentMap){ WordNum;敏感词=wordif(current map . get(' laster ')===true){//表示单词的结尾已达到flag=true打破;} } else { break} }//构词if(WordNum 2){ flag=false;}返回{标志,敏感词};}/*** @description*判断文本中是否有敏感词* @ param {any} txt * @返回*/public filter sensitive word(txt,sensitive map){ let match result={ flag : false,sensitive word : ' ' };//滤除常量txt trim=txt。将(/[ u4e 00- u9 fa 5 u 0030- u 0039 u 0061- u 007 a u 0041- u 005 a]/g替换为(让I=0;i txtTrim.lengthI){ match result=check敏感词(敏感映射,txtTrim,I);if(match result . flag){ console . log(`敏感词:${matchResult .敏感词} `);打破;} }返回matchResult}效率
为了看DFA的效率,我做了一个简单的小测试。测试文本长度为5095个汉字,敏感词词典中有2000个敏感词。比较算法是DFA算法和字符串本机对象提供的索引。
//简单字符串匹配-indexofensitivewords。foreach ((word)={if (ss。(单词)索引!==-1) {console.log(word) }})这两种算法分别执行100次,得到如下结果

直观可见,DFA的平均耗时约为1ms,最大为5 msindexOf模式的平均时间约为9ms,最长时间为14ms,因此DFA在效率上具有明显优势。
摘要
以上就是边肖介绍的js实现敏感词过滤算法和实现逻辑。希望对大家有帮助。如果你有任何问题,请给我留言,边肖会及时回复你。非常感谢您对我们网站的支持!

 萌导航
萌导航 pp加速器
pp加速器 邮乐网
邮乐网 yowa云游戏手机版
yowa云游戏手机版 哈屏壁纸免费版
哈屏壁纸免费版 安卓壁纸大师app
安卓壁纸大师app webtoon漫画中文版
webtoon漫画中文版 小黄人影视2024最新版
小黄人影视2024最新版 南瓜车管家
南瓜车管家 锦江酒店
锦江酒店 看怀集
看怀集 抬腕应用商店最新
抬腕应用商店最新 腾讯会议手机版
腾讯会议手机版 圣婴阅读
圣婴阅读 柠檬英语软件
柠檬英语软件 苗苗清理大师
苗苗清理大师 夸磁浏览器app
夸磁浏览器app 提瓦特小助手安卓版
提瓦特小助手安卓版 硬汗健身
硬汗健身 亲亲漫画
亲亲漫画





