1.爬虫:爬虫,是一种按照一定的规则,自动地抓取网页信息的程序或者脚本;利用开发实现一个简单的爬虫案例,爬取老板直聘网站的网前端相关的招聘信息,以广州地区为例;
2.脚本所用到的开发模块
表达用来搭建一个服务,将结果渲染到页面
大喝模板引擎
再见用来抓取页面的数据
要求用来发送请求数据(具体可查:https://www.npmjs.com/package/requests)
异步非同步(异步)用来处理异步操作,解决请求嵌套的问题,脚本中只使用了async.whilst(测试、迭代、回调),具体可见:https://caolan.github.io/async/
3.实现流程:
首先先获取到所爬取页面的网址,打开老板直聘网站,搜索网前端既可以获取到https://www.zhipin.com/c101280100-p100901/?page=1ka=page-next

然后通过铬浏览器打开F12,获取到信息中多对应的数字正射影像图节点,即可知道想要获取信息;
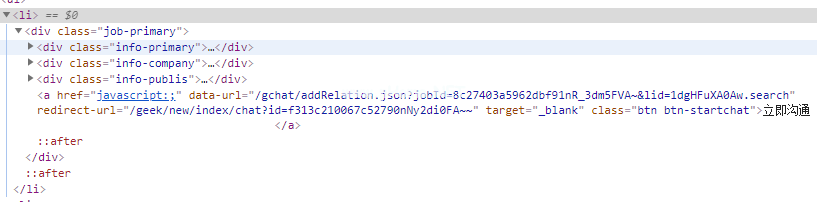
4.代码实现
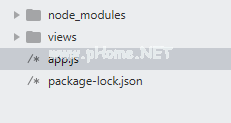
目录结构:
app.js
var cherio=require(' cherio ');var requests=require(' requests ');var async=require(' async ');var express=require(' express ');var swig=require(' swig ');var app=express();痛饮。setdefaults({ cache : false });app。set(' view ',')./view/');app.set('视图引擎,' html ');app.engine('html ',swig。render file);app.get('/'),function(req,res,next){ var page=1;//当前页数定义变量列表=[];//保存记录异步。while(function(){ 0返回第11页;},函数(回调){ requests(` https://www .智品。com/c 101280100-p 100901/?page=${page}ka=page-next `).on('data ',function(chunk){ var $=cheerio。加载(块。tostring());$('.主要工作').每个(函数(){ var company=$(this)).查找('。信息公司。公司短信。名称')。text();var job_title=$(this).查找('。初级信息。名字。职称')。text();定义变量工资=$(这个)。查找('。初级信息。名字。红色')。text();定义变量描述=$(这个).查找('。信息公司。公司文本p ').text();定义变量面积=$(这个).查找('。信息-主p ').text();var item={ company:company,job_title:job_title,salary:salary,description:description,area : area };名单。推送(项目);});页面;回调();}).on('end ',function(err){ if(err){ console。日志(err);} if(page==10){ RES . render(' index ',{ list 3360 list });} });},函数(错误){控制台。日志(err);} );});//监听app。听(8080);视图/索引。超文本标记语言页面
!DOCTYPE html html lang=' en ' head meta charset=' UTF-8 ' title document/title/head style table { width :1300 px;border:1px固体# ccc边界崩溃:崩溃;文本对齐:中心;margin:0 auto} td,tr,th{ border:1px固态# ccc边界崩溃:崩溃;} tr { height:30px线高: 30px}/stylebody表和tr th公司名称/th公司地址/th薪资/th公司描述/th岗位名称/th/tr/列表% }中列表的ad t正文{ % tr TD { { list }。公司} }/TD { {列表。区域} }/TD TD { {列表。薪资} }/TD { {列表。描述} }/TD { {列表。job _ title } }/TD/tr { % end for % }/t body/table/body/html 5 .启动
直接通过node app.js启动即可;
6.运行结果(http://localhost:8080),只截取部分数据

总结
以上所述是小编给大家介绍的开发实现简单的爬虫功能,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!

 萌导航
萌导航 pp加速器
pp加速器 邮乐网
邮乐网 yowa云游戏手机版
yowa云游戏手机版 哈屏壁纸免费版
哈屏壁纸免费版 安卓壁纸大师app
安卓壁纸大师app webtoon漫画中文版
webtoon漫画中文版 小黄人影视2024最新版
小黄人影视2024最新版 南瓜车管家
南瓜车管家 锦江酒店
锦江酒店 看怀集
看怀集 抬腕应用商店最新
抬腕应用商店最新 腾讯会议手机版
腾讯会议手机版 圣婴阅读
圣婴阅读 柠檬英语软件
柠檬英语软件 苗苗清理大师
苗苗清理大师 夸磁浏览器app
夸磁浏览器app 提瓦特小助手安卓版
提瓦特小助手安卓版 硬汗健身
硬汗健身 亲亲漫画
亲亲漫画





