一、前言
这里我就不重复Hadoop的原理架构了,但是我可以自己做。本文只介绍Hadoop-3.1.2完全分布式环境(我使用三个虚拟机来构建)。
第一步:
准备安装包和工具:
Hadoop-3.1.2.tar.gzjdk-8u221-linux-x64.tar.gz(Linux环境下的JDK)certos-7-x86 _ 64-DVD-1810 . iso(centos image)工具:WinSCP(用于向虚拟机上传文件)、SecureCRTP或table(用于操作虚拟机,可以复制粘贴Linux命令。您可以不使用此工具,但必须手动键入命令),VMware Workstation Pro
安装虚拟机:我使用的是VMware Workstation Pro,需要激活。(最大限度地减少虚拟机主机的安装,然后在配置Hadoop后克隆两个从机)
配置虚拟机:修改用户名、设置静态IP地址、修改主机文件、关闭防火墙、安装Hadoop、安装JDK、配置系统环境、配置无密码登录(必要)。
配置Hadoop:配置hadoop-env.sh、hdfs-site.xml、core-site.xml、mepred-site.xml、yarn-site.xml、workers文件(在Hadoop-2,从文件用于存储从节点的主机名或IP地址)
克隆虚拟机:克隆两个从机,主机名分别为Slave1和Slave2。然后修改Slave的Hadoop配置。
namenode格式化:分别在Master、Slave1和Slave2上执行hadoop namenode -format命令。
启动hdfs和纱线:在主机上执行start-all.sh命令。启动完成后,执行jps命令查看进程,进程应该包括三个进程:名称节点、辅助名称节点和资源管理器。从属节点上有数据节点和节点管理器进程。
检查测试:首先修改真实主机的主机(IP地址与Master的映射),在浏览器中输入Master:9870,输入hdfs,点击上面的datanode,看到下面有两个节点;输入Master:8088进入资源调度管理(纱线)
好了,开始吧。
第二,准备工具
Hadoop-3.1.2.tar.tz下载地址:http://mirror . bit . edu.cn/Apache/Hadoop/common/Hadoop-3 . 1 . 2/Hadoop-3 . 1 . 2 . tar . gz
Jdk-8u221-linux-x64.tar.gz下载地址:https://
CentOS下载地址:http://isoredirect.centos.org/centos/7/ISOS/x86 _ 64/CentOS-7-x86 _ 64-DVD-1810 . iso
WinSCP下载地址: https://winscp.net/eng/download.php
SecureCRTP或可下载地址: http://fs2 . download 82.com/software/bbd 8 ff 9 DBA 17080 c0c 121804 efbd 61d 5/securerct-portable/scrt 675 _ u3.exe
VMware Workstation Pro的下载地址:http://download 3 . VMware.com/software/wkst/file/VMware-Workstation-full-15 . 1 . 0-13591040 . exe
使用VMware工作站专业版密钥:
YG5H2-ANZ0H-M8ERY-TXZZZ-YKRV8
UG5J2-0ME12-M89WY-NPWXX-WQH88
UA5DR-2ZD4H-089FY-6YQ5T-YPRX6
第三,安装虚拟机
这一步就省略了,详细内容稍后会公布
第四,配置虚拟机
1.修改用户名:
主机名ctl -静态集-主机名主机
2.设置静态IP地址
首先,检查自动获取的网关和域名系统,并写下来
[[email protected]~]# cat/etc/resolv . conf #由networkmanagermanameserver 192.168.28.2//dnsbbr[[email protected]~]# Ip路由表目标网关genmask标志MSS窗口irtt iface默认值192 . 168 . 28 . 2(网关)0 . 0 . 0 ug 000 ens 33192 . 168 . 28 . 0 . 0 255 . 255 . 0。
进入界面后,按“I”键进入编辑模式,对图中标记的红色部分进行修改或添加。“静态”是指静态地址,“网络掩码”是指子网掩码,网关是指网关,可以按照上一步所述进行设置。修改后按“esc”退出编辑模式。输入“:wq”保存并退出。然后输入以下代码更新网络配置。
系统重启网络
3.修改主机文件
注:我将Master的IP地址设置为192.168.28.132,Slave1和Slave2分别设置为192.168.28.133和192.168.28.134
输入以下代码修改主机文件(在真实主机中也需要添加):
vi /etc/hostsbr添加:br 192。168 .28 .132主br 192。168 .28 .133奴隶1 br 192。168 .28 .134奴隶.关闭防火墙
关闭防火墙代码:
启动脚本停止firewalld.service //临时关闭启动脚本禁用firewalld.service //设置开机不自启5.安装大数据和爪哇岛开发工具包
先创建两个文件夹:
mkdir /tools /用来存放安装包mkdir /bigdata //存放解压之后的文件夹使用WinSCP上传压缩包:登录后找到已下载好的压缩包按如下步骤点击上传即可。

上传文件后,虚拟机端进入工具文件夹并解压文件:
CD/工具/进入工具文件夹tar-zvxf JDK-8u 221-Linux-x64 . tar . gz-C/大数据//解压文件到数据量大目录下brtar -zvxf hadoop-3.1.2.6 .配置系统环境
vi ~/.bash_profile添加:导出JAVA _ HOME=/大数据/JDK 1。8 .0 _ 221导出JRE _ HOME=$ JAVA _ HOME/JRE导出CLASPATH=。美元CLASPATH :美元JAVA _ HOME/lib :美元JRE _ HOME/lib导出路径=$ PATH :美元JAVA _ HOME/bine :美元JRE _ HOME/bine导出HADOOP _ HOME=/大数据/HADOOP-3。1 .2导出HADOOP_INSTALL=.保存退出,让环境变量生效:来源~/。bash_profile 7 .配置免密登录(重要)
ssh-keygen -t rsa(直接回车3次)cd ~/.ssh/ssh-copy-id-I id _ RSA。pub[电子邮件保护]ssh-copy-id-I id _ RSA。pub[电子邮件保护]ssh-copy-id-I id _ RSA。pub[电子邮件保护]测试是否成功配置(在配置完奴隶之后测试):ssh Slave1可以登录到Slave1节点五、配置大数据
Hadoop-3.1.2中有许多坑,在2X版本中有些默认的不需要特别配置,但在Hadoop-3.1.2中需要。
hadoop-env.sh配置:
CD/大数据/Hadoop-3。1 .2/etc/Hadoop/VI Hadoop-env。嘘添加:导出JAVA _ HOME=/大数据/JDK 1。8 .0 _ 221导出HADOOP _ HOME=/大数据/HADOOP-3。1 .2导出路径=$ PATH :/大数据/HADOOP-3。1 .2/binexport HADOOP _ OPTS='-Djava。图书馆。PATH=$ { HADOOP _ HOME }/lib/native ' export HADOOP _ PID _ DIR=/大数据/HADOOP-3。1 .2/pids//PID存放目录,若没有此配置则默认存放在终端监督程式(终端监控程序的缩写)临时文件夹中,在启动和关闭分布式文件系统时可能会报错# export HADOOP _ ROOT _ LOGGER=DEBUG,console //先注释掉,有问题可以打开,将调试信息打印在安慰上hdfs-site.xml:
配置属性namedfs.replication/name//冗余度,默认为3价值1/价值/属性属性namedfs.datanode.data.dir/name值/大数据/Hadoop-3。1 .2/DFS/tmp/数据/值/属性属性namedfs.namenode.name.dir/name值/大数据/Hadoop-3。1 .2/DFS/tmp/名称/值/属性属性namedfs.permissions/name值false/值/属性/配置映射。网站。XML :
配置属性namemapreduce.framework.name/name值纱/值/属性属性namemapred.job.tracker/name值主:9001/值/属性/配置纱-站点。xml:
配置属性名称码。节点管理器。辅助服务/名称值MapReduce _ shuffle/值/属性属性nameyarn.resourcemanager.hostname/name值主/价值/财产财产名称院子。log-aggregation-enable/name值true/value/property属性name yard。日志聚合。保留-秒/名称值604800/值/属性/配置核心-站点。XML :
配置属性namefs.defaultFS/name值HDFS ://硕士:9000/价值/财产属性namehadoop.tmp.dir/name值/大数据/Hadoop-3。1 .2/tmp/value/property/configuration workers :把默认的本地主机删掉
奴隶1 192号。168 .28 .133奴隶2 192。168 .28 .134纱-环境卫生添加:
纱_资源管理器_用户=root Hadoop _ SECURE _ DN _ USER=YarNyarn _ NODEMANAGER _ USER=root进入/bigdata/hadoop-3.1.2/sbin,修改开始-dfs.sh,停止-dfs.sh,都添加:
HDFS _数据节点_用户根HDFS数据节点_安全_用户=hdfsHDFS _ NAMENODE _ USER=root HDFS _次要名称ENODE _ USER=root六、克隆虚拟机
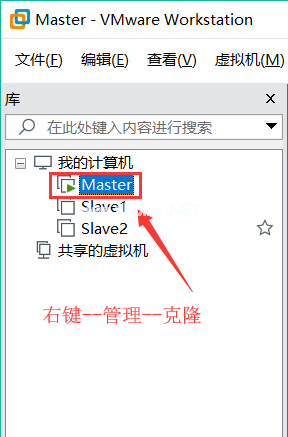
克隆两个从节点虚拟机,主机名分别为Slave1和Slave2(需要在虚拟机中修改),然后修改IP地址(具体方法同上)重启网络和虚拟机。
重启后,格式化名称节点:分别在主机、从机1和从机2上执行以下步骤:
Hadoop命名节点格式在Master上执行
开始-所有。sh //开始hdfs和纱线
完成后,用jps检查流程:
[[电子邮件保护] ~] # JPS 7840资源管理器8164 JPS 7323名称节点7564辅助名称节点两个从属进程:
它包含以下两个:数据节点管理器七。支票
浏览器输入:在浏览器中输入Master:9870进入hdfs管理页面,点击上面的datanode,看到下面有两个节点;

输入Master:8088进入资源调度管理(纱线)

摘要
以上是边肖介绍的Hadoop-3.1.2完全分布式环境(Windows 10)的构建过程的详细说明。希望对大家有帮助。如果你有任何问题,请给我留言,边肖会及时回复你。非常感谢您对我们网站的支持!如果你觉得这篇文章对你有帮助,请转载,请注明出处,谢谢!

 萌导航
萌导航 pp加速器
pp加速器 邮乐网
邮乐网 yowa云游戏手机版
yowa云游戏手机版 哈屏壁纸免费版
哈屏壁纸免费版 安卓壁纸大师app
安卓壁纸大师app webtoon漫画中文版
webtoon漫画中文版 小黄人影视2024最新版
小黄人影视2024最新版 南瓜车管家
南瓜车管家 锦江酒店
锦江酒店 看怀集
看怀集 抬腕应用商店最新
抬腕应用商店最新 腾讯会议手机版
腾讯会议手机版 圣婴阅读
圣婴阅读 柠檬英语软件
柠檬英语软件 苗苗清理大师
苗苗清理大师 夸磁浏览器app
夸磁浏览器app 提瓦特小助手安卓版
提瓦特小助手安卓版 硬汗健身
硬汗健身 亲亲漫画
亲亲漫画





