万能OCR字符识别软件是一款非常不错的字符识别软件。该软件界面简洁清爽,所有功能直接显示在桌面上,可以帮助用户识别图片、门票、PDF文档。PDF是一种常见的文件格式,这种格式的文件需要在专门的软件中进行编辑。如果没有PDF编辑器和格式转换软件,可以通过识别文档的形式来识别PDF文件中的内容,并以Word等格式保存。然后边肖会给大家详细介绍万能OCR字符识别软件识别PDF文档的具体操作方法。有需要的朋友可以看一看,收藏起来。
第一步。首先,打开软件。我们在界面右下角找到“PDF文档识别”选项,点击该选项进入PDF文档识别页面。
2.然后,在PDF文档识别页面,我们找到页面左下方的“添加文件”按钮,点击该按钮进入文件添加页面。
3.在文件添加页面,我们会选择需要识别的PDF文档,然后点击页面右下角的“打开”按钮。
4.将文件添加到软件后,我们在界面顶部找到“页码选择”选项,点击选项底部的“全部”按钮打开页面选择窗口,在窗口中设置要识别的页面,点击窗口右下角的“确定”按钮。
5.接下来,在界面左下方找到“输出格式”选项,我们根据自己的需要设置其后面的输出格式,如下图所示。
6.然后在界面左下方找到“输出目录”选项。我们单击该选项后面的下拉按钮,并在下拉框中设置输出目录。如果选择“自定义目录”,还需要点击后面的“更改路径”按钮。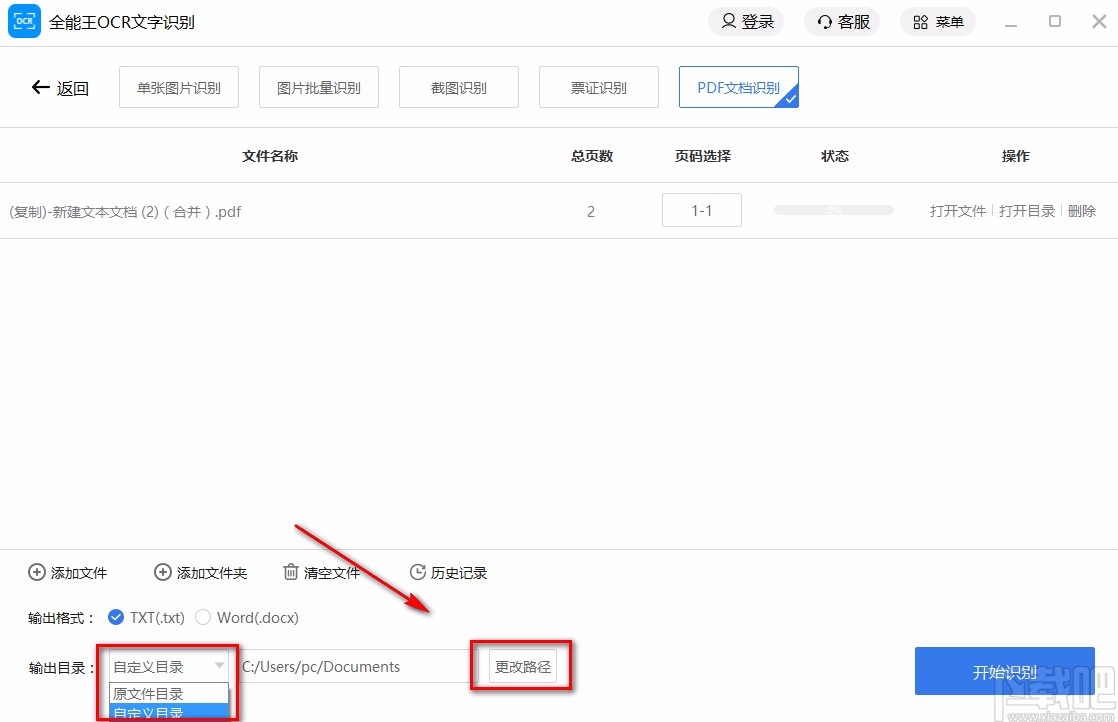
7.点击“更改路径”按钮后,界面上会出现文件保存路径选择页面。我们将在页面中选择文件保存位置,然后点击页面右下角的“选择文件夹”按钮。
8.然后在界面右下角找到蓝色的“开始识别”按钮,我们点击这个按钮就可以开始识别PDF文档内容了。
识别9.PDF后,我们在界面顶部找到“状态”列,可以看到列底部显示的进度是100%;单击其后面的“打开文件”按钮查看识别的文件。
以上就是边肖编写的万能OCR文字识别软件识别PDF文档的具体操作方法。方法简单易懂,有需要的朋友可以看看。希望这篇教程对大家有所帮助。

 萌导航
萌导航 pp加速器
pp加速器 邮乐网
邮乐网 yowa云游戏手机版
yowa云游戏手机版 哈屏壁纸免费版
哈屏壁纸免费版 安卓壁纸大师app
安卓壁纸大师app webtoon漫画中文版
webtoon漫画中文版 小黄人影视2024最新版
小黄人影视2024最新版 南瓜车管家
南瓜车管家 锦江酒店
锦江酒店 看怀集
看怀集 抬腕应用商店最新
抬腕应用商店最新 腾讯会议手机版
腾讯会议手机版 圣婴阅读
圣婴阅读 柠檬英语软件
柠檬英语软件 苗苗清理大师
苗苗清理大师 夸磁浏览器app
夸磁浏览器app 提瓦特小助手安卓版
提瓦特小助手安卓版 硬汗健身
硬汗健身 亲亲漫画
亲亲漫画





